AWS S3の仕組みをわかりやすく解説|オブジェクトストレージの基本とAWSサービスとの連携
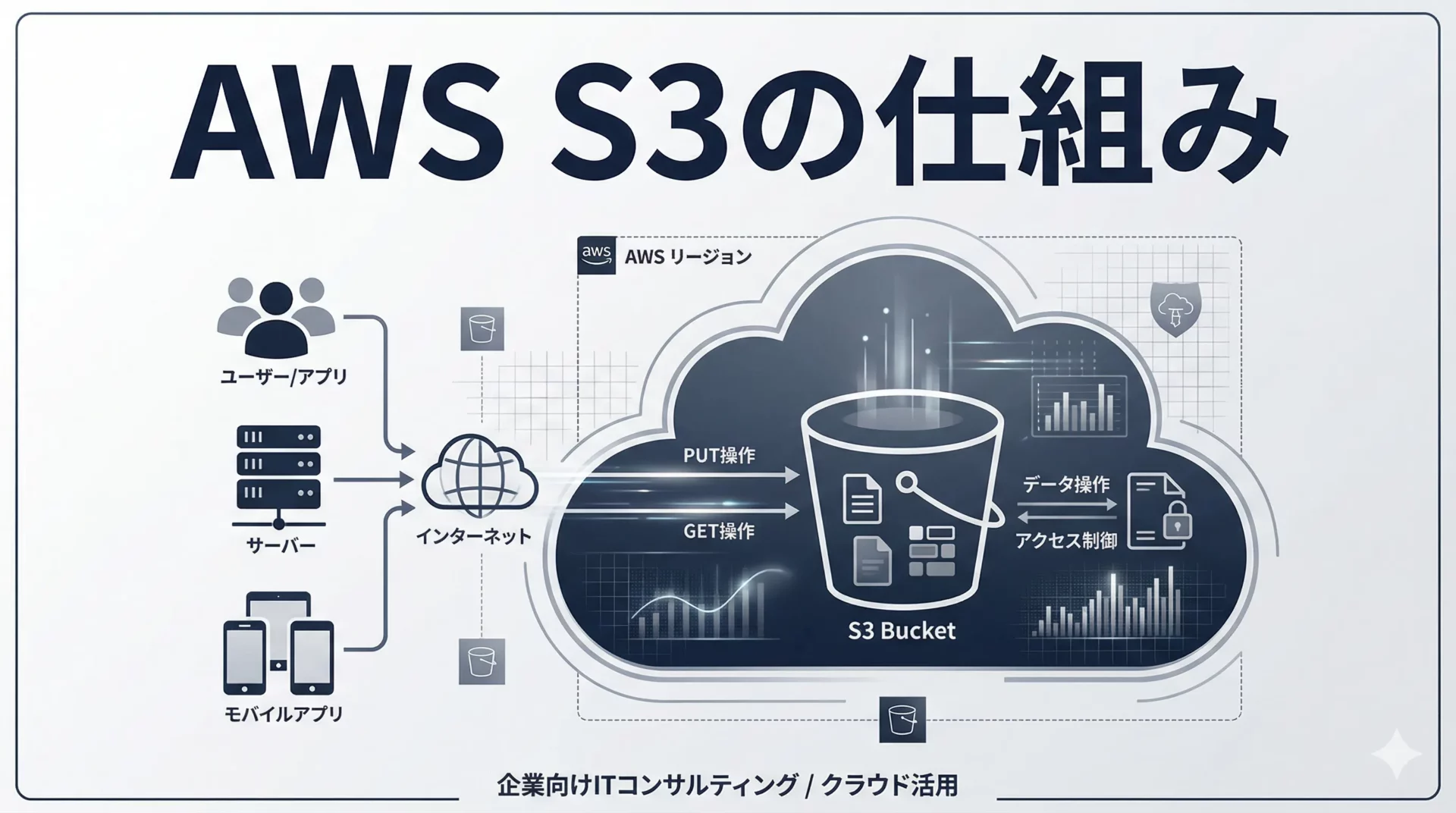
「AWS S3はよく使っているが、内部でどう動いているのかよくわからない」「オブジェクトストレージとファイルストレージの違いが曖昧」——S3を使い始めた方や、設計・構成を見直したい方からよくいただく疑問です。
本記事では、AWS S3の仕組みをオブジェクトストレージの基本から解説し、バケット・オブジェクト・アクセス制御の構造と、EC2・Lambda・CloudFrontなど他のAWSサービスとの連携方法を整理します。
この記事でわかること
- オブジェクトストレージとは何か(ファイル・ブロックストレージとの違い)
- S3の基本構造(バケット・オブジェクト・キーの関係)
- アクセス制御の仕組み(IAM・バケットポリシー・ACL)
- EC2・Lambda・CloudFront・RDSとの連携パターン
- S3を使う主なユースケース
想定読者
- S3を使い始めたばかりで仕組みを理解したいエンジニア・情シス担当者
- S3の設計・構成を見直したい方
- AWSのストレージサービスの違いを整理したい方
目次
オブジェクトストレージとは?
AWS S3はオブジェクトストレージサービスです。オブジェクトストレージを理解するには、他のストレージ方式との違いを整理するのが早道です。
| ストレージ方式 | 代表サービス | データの管理単位 | 主な用途 |
|---|---|---|---|
| オブジェクトストレージ | AWS S3 | オブジェクト(ファイル+メタデータ) | 画像・動画・バックアップ・ログ |
| ファイルストレージ | Amazon EFS、NAS | ファイル・フォルダ階層 | 共有ファイルサーバー、アプリの共有領域 |
| ブロックストレージ | Amazon EBS | ブロック(固定サイズのデータ断片) | OS・データベース・高速I/Oが必要な用途 |
オブジェクトストレージの特徴:
- フラットな名前空間:フォルダ階層ではなく、「バケット名 + キー(パス文字列)」でデータを識別
- メタデータの付与:ファイルに任意のメタデータ(作成者・用途・有効期限など)を付けられる
- スケーラビリティ:容量制限なし、データ量が増えても自動でスケール
- HTTP/REST API:ファイルシステムのマウント不要で、APIを通じて読み書き
S3の基本構造:バケット・オブジェクト・キー
S3の構造は大きく3つの要素で成り立っています。
バケット(Bucket)
バケットはS3におけるデータの格納コンテナです。
- グローバルに一意なバケット名が必要(世界中で同じ名前は使用不可)
- AWSリージョンごとに作成(例:東京リージョン =
ap-northeast-1) - 1つのAWSアカウントで最大100バケットまで作成可能(上限緩和申請で増やせる)
- バケット単位でアクセス制御・バージョニング・ライフサイクルポリシーを設定
オブジェクト(Object)
オブジェクトはS3に保存されるデータの単位です。
- 1オブジェクトの最大サイズは5TB
- データ本体(バイナリ)+メタデータ(HTTPヘッダー形式)で構成
- 一度アップロードしたオブジェクトを「上書き」する場合、実際には新しいバージョンが作成される(デフォルトでは上書き)
- バージョニングを有効にすると過去バージョンを保持・復元できる
キー(Key)
キーはバケット内でオブジェクトを一意に識別するための文字列です。
例:
バケット名:my-company-backup
キー:2026/03/logs/access.log
フルパス(S3 URI):s3://my-company-backup/2026/03/logs/access.log/ を含むキーを使うことでフォルダのような見た目になりますが、実際にはフォルダは存在せず、すべてフラットなキーです。S3コンソールはキーの / を解釈して疑似フォルダとして表示しています。
アクセス制御の仕組み
S3のアクセス制御は複数のレイヤーで構成されています。
| 制御方法 | 適用範囲 | 主な用途 |
|---|---|---|
| IAMポリシー | AWSユーザー・ロール単位 | 「このIAMユーザーはS3のGetObjectのみ許可」 |
| バケットポリシー | バケット単位(JSONで記述) | 「特定IPアドレスからのアクセスのみ許可」「特定アカウントへの公開」 |
| ACL(アクセス制御リスト) | オブジェクト単位 | レガシーな制御方法(現在は非推奨) |
| ブロックパブリックアクセス | バケット・アカウント単位 | パブリックアクセスを一括遮断(デフォルト有効) |
2023年4月以降のデフォルト設定:新規バケットはブロックパブリックアクセスが有効になっており、意図しない公開を防ぐ設計になっています。パブリック公開が必要な場合(静的ウェブサイトホスティング等)は明示的にオフにする必要があります。
バケットポリシーの例
特定のIAMロールからのみGetObjectを許可する例:
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"AWS": "arn:aws:iam::123456789012:role/MyAppRole"
},
"Action": "s3:GetObject",
"Resource": "arn:aws:s3:::my-bucket/*"
}
]
}AWSサービスとの連携パターン
S3は単独で使われることは少なく、他のAWSサービスと組み合わせることで真価を発揮します。
AWS S3の設計・構築でお困りですか?
c3indexでは、S3を含むAWSクラウド環境の設計・構築・運用支援を行っています。まずはお気軽にご相談ください。
EC2との連携
EC2インスタンスからS3へのアクセスは、IAMロールをEC2に付与するのが基本パターンです。アクセスキーをコードに埋め込む必要がなく、セキュリティ的に安全です。
主なユースケース:
- アプリケーションが生成したログをS3に定期保存
- EC2上のWebアプリの静的ファイル(画像等)をS3から取得
- EC2バックアップのS3保存(AWS Backupとの組み合わせ)
注意点:EC2からS3へのデータ転送は、同一リージョン内であれば無料です。異なるリージョン間はデータ転送料が発生します。
Lambdaとの連携
S3とLambdaの連携は、イベントドリブン処理の代表パターンです。
S3にファイルアップロード
↓ イベントトリガー
Lambda関数が起動
↓
ファイルの変換・加工・通知などを実行
↓
処理結果を別のS3バケットに保存具体的なユースケース:
- 画像アップロード時に自動でサムネイル生成
- CSVアップロード時にDynamoDB・RDSにデータ投入
- ログファイルアップロード時にアラート通知
CloudFrontとの連携
S3単体でファイルを配信すると、アクセスのたびにデータ転送料が発生します。CloudFront(CDN)を前段に置くことで:
- 転送コストの削減:CloudFrontのキャッシュからコンテンツを配信し、S3への直接リクエストを減らす
- 配信速度の向上:エッジロケーションから配信することで、世界中のユーザーへの遅延を最小化
- セキュリティ強化:S3バケットをプライベートに保ったまま、CloudFront経由でのみ公開できる(OAC:Origin Access Control)
静的ウェブサイト・商品画像・動画コンテンツの配信では、S3+CloudFrontの組み合わせが定番構成です。
RDS・データ分析サービスとの連携
| 連携先 | 用途 |
|---|---|
| Amazon RDS | DBのバックアップをS3にエクスポート、CSVをS3経由でインポート |
| Amazon Athena | S3上のCSV・Parquetファイルに対してSQLクエリを直接実行 |
| AWS Glue | S3上のデータをETL処理してデータウェアハウスに投入 |
| Amazon Redshift | S3からデータをCOPYコマンドで一括ロード |
S3をデータの「中間置き場(ステージング領域)」として活用することで、様々なデータパイプラインを構築できます。

S3の主なユースケース
静的ウェブサイトホスティング
HTML・CSS・JavaScript・画像などの静的ファイルをS3に配置し、ウェブサイトとして公開できます。サーバーレスのため管理コストが低く、CloudFrontと組み合わせることで高速・低コストな配信が可能です。
バックアップ・アーカイブ
オンプレミスサーバーや基幹システムのバックアップ先として広く使われます。S3 Glacier Deep Archiveを使えば約0.2円/GB/月で長期保存が可能で、オンプレのNASと比較してコストを大幅に削減できます。

機械学習・データレイク
大量のトレーニングデータ・ログデータをS3に集約し、AmazonSageMaker・Athena・Redshiftなどで分析・学習に使うデータレイク構成の中核を担います。
製造業での活用例
- 設備点検記録の長期保存:点検写真・動画をS3 Glacierに保存(法令対応)
- CAD・BOMデータのバックアップ:設計ファイルの世代管理とオフサイトバックアップ
- 生産ログのデータ分析基盤:PLC・センサーデータをS3に集積し、Athenaで分析
よくある質問
Q. S3はファイルサーバーの代替として使えますか?
A. 用途によります。S3はオブジェクトストレージのため、WindowsのネットワークドライブのようなSMBプロトコルでの共有には対応していません。ファイル共有用途には「Amazon EFS」(Linux向け)や「AWS Storage Gateway」(オンプレとの連携)が適しています。単純なファイルのアップロード・ダウンロード・共有URLの発行であればS3で対応可能です。
Q. S3のデータは暗号化されていますか?
A. デフォルトで保存時の暗号化(SSE-S3)が有効です。AWS KMSを使ったカスタマーマネージドキー(SSE-KMS)や、クライアント側での暗号化も選択できます。通信はHTTPS(TLS)で暗号化されています。
Q. S3バケットのリージョンはどう選べばよいですか?
A. ①アクセス元(EC2・ユーザー)に近いリージョンを選ぶことでレイテンシを下げられます。②同一リージョン内のデータ転送は無料のため、主に連携するAWSサービスと同じリージョンにするのが基本です。③法令・データレジデンシー要件がある場合は指定リージョンに固定します。
Q. S3のバージョニングとは何ですか?
A. バージョニングを有効にすると、同じキーのオブジェクトを上書きしても過去バージョンが保持されます。誤削除・誤上書きからの復元が可能になりますが、古いバージョンもストレージ料金が発生するため、ライフサイクルポリシーで古いバージョンの自動削除を設定することをおすすめします。
まとめ
- AWS S3はオブジェクトストレージ。データを「バケット」に格納し、「キー」で識別する
- ファイルストレージ(EFS)・ブロックストレージ(EBS)とは用途・特性が異なる
- アクセス制御はIAMポリシー+バケットポリシーの組み合わせが基本(ACLは非推奨)
- EC2・Lambda・CloudFront・Athenaなど多くのAWSサービスと連携し、様々なアーキテクチャを実現
- 製造業では設備記録の長期保存・CADバックアップ・生産ログ分析基盤として活用

AWS S3の設計・構築はc3indexへ
c3indexでは、AWS S3を含むクラウド環境の設計・構築・運用支援を一貫して対応しています。「S3を使ったバックアップ基盤を作りたい」「CloudFrontとの構成を最適化したい」といったご相談から歓迎です。
CATEGORIES
CATEGORIES





